Recently, I was on a call with a friend who mentioned he was having an infrastructure problem with his home lab setup. He uses Docker Compose to manage his services, and wants to introduce health checks to all his images so he can use a tool like autoheal to restart unhealthy ones. However, some of the containers he uses in his setup are based off of distroless images, which prevented him from using existing tools in the container like curl and wget.
I’ve been working to improve my Rust skills, and a lot of what I do is related to infrastructure. This seemed like an interesting project to sink my teeth into, so I volunteered to build something to help.
A Word on Distroless
“Distroless” is a container setup in which the final image that you ship contains only the bare-minimum dependencies required to run your service. Some languages, like Go and Rust, are predominantly statically-linked- which means that it’s possible for them to have no external dependencies. For an application that is fully statically linked, none of the standard things most applications rely on (like libc) need to exist in the container, so you get a very tiny final image. That is exciting for several reasons that deserve their own blog post, but not great if you need to use tools that rely on those standard libraries.
First Attempts with Existing Tools
When we were talking it over, my friend mentioned he tried a few things to get these checks to work. Ultimately, he needed something that could make HTTP calls and return a status code for the health check, so at first he tried:
- Mounting the
curlbinary in the container. This didn’t work because it’s dynamically linked and the libraries weren’t mounted - Mounting the
wgetbinary in the container. Similarly, this is dynamically linked
Trying to mess around with mounting libraries was not desirable, and neither was building a new container based on the application used- those things are a little too finicky and it’s usually better to rely on the existing publishing infrastructure managed by the people actually writing these apps.
The Requirements
We chatted it over and came up (informally) with a small list of what was needed of the tool. Writing this up now, we can loosely split them up by priority as I understood them at the start:
P0 (main priority):
- The tool needs to be able to make an HTTP GET request to a URL specified by the command line
- On a successful request, it needs to return an exit code of 0
- On any failure, it needs to return a non-zero exit code
- The tool needs to be fully statically linked so it can run on any x86_64 container, including distroless
P1 (key, but less important):
- The final binary needs to be reasonably small. The base container we were working with was ~4-5 mb in size, and I did not want to significantly bloat it
- The tool needs to be reasonably efficient. It should not meaningfully increase the resource requirements to run the application.
- The tool needs to be reasonably easy to use.
P2 (nice-to-haves):
- The tool should be easy to consume. This could mean a pipeline, publishing it to a package registry, or even making the code available in an easy-to-build way.
- Support for TLS as an optional feature
Benchmarking
As part of the P1-1 requirement, I wanted to also check what the size of the existing HTTP clients are, since they’re standard and contain quite a few features. If I’m building a minimal application, I should strive to not be substantially larger than existing tools that are more comprehensive. Ideally, my application should be even smaller than what is available.
I picked the alpine container to check the size of these binaries and their libraries since alpine tends to be very minimal. First, I checked the size of wget and its dependencies:

Then, I checked curl:
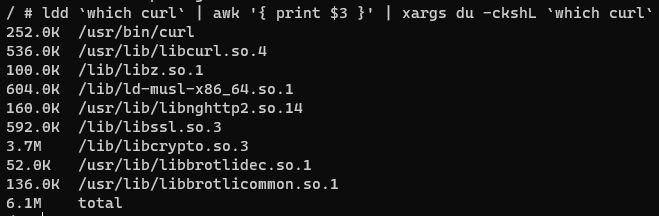
Now, I have my target to beat: 1.4 mb for wget and 6.1 mb for curl. Any binary that I build that has minimal functionality should be within that ballpark.
Implementing HttpGet
Preliminaries
From previous development experience (generally, and in Rust), there were a few things that I knew off-hand would be relatively simple:
- I had existing Rust projects that had Github Actions workflow files I could reuse/adapt, so testing/releasing the finished binary was going to be fairly trivial
- I knew the Rust Cookbook has an example on how to make web requests, which is the core functionality of this tool
- Debug information and symbols could be stripped from the final binary to make it smaller
- By using the
x86_64-unknown-linux-musltarget in Rust, the final binary is statically linked
Armed with this knowledge, I set out to create httpget.
First Pass Implementation
The first implementation of httpget focused around using the reqwest library as that was what the cookbook recommended. The whole implementation took about 40 minutes to create from start to finish, mostly because I was already familiar with reqwest and tokio. Since TLS support was a P2, I started first with limiting the features of these crates to try to have the most compact binary. After some fiddling, version httpget v0.1.2 was published on GitHub by the pipeline.
use reqwest::Client;
use std::env;
async fn run(endpoint: &str) {
let client = Client::builder().build().unwrap();
let res = client.get(endpoint).send().await;
if res.is_err() {
panic!("Can't reach route {}", endpoint);
}
}
fn main() {
let args: Vec<String> = env::args().collect();
if args.len() > 2 {
panic!("Too many arguments!")
}
let endpoint = args.last().unwrap();
tokio::runtime::Builder::new_current_thread()
.enable_time()
.enable_io()
.build()
.unwrap()
.block_on(run(endpoint))
}
#[cfg(test)]
mod tests {
use super::*;
#[tokio::test]
async fn can_reach_google() {
run("http://google.com").await
}
}
Looking over our requirements, it mostly looked like it matched quite a few of them:
| P0 (main priorities) | P1 (key, but less important) | P2 (nice-to-haves) |
|---|---|---|
| HTTP GET requests | 2.87 mb binary | Automatic Github publishing |
| On success, 0 exit code | Fast library, fast language | Smaller than curl |
| On failure, non-zero exit code | Easy CLI-ish | |
| Statically linked |
However, there’s some stuff I immediately didn’t like about this solution:
- No way to have TLS support. This became a problem since
httpgetwas emitting panics when trying to reach sites likehttp://github.com, presumably because ofHTTPSredirects. This would not be a problem in my friend’s home lab since they only neededhttp, but was a limitation. - While 2.87 mb is relatively small (a little under half the
curlbenchmark), that seemed very excessive. I could not find a way to remove thetokiodependency fromreqwest, which means that it was not possible to use this recommended crate without bundling an entire async runtime in the binary. It didn’t really matter too much since this isn’t being run on an embedded system, but it didn’t sit right with me that the tool would be this “big” with such limited functionality.
Fixing Incorrect Requirements
After presenting this version to my friend, we chatted a bit more and eventually I realized I had misunderstood one of the P0 requirements: For healthchecks, Docker requires very specific exit codes. For success, it does indeed use a 0 exit code (P0-2), but for failures it requires an exit code of 1. This means that P0-3 needed to be re-written:
P0-3: On any request failure, the tool should return an exit code of 1.
Unfortunately, since v0.1.2 relied on panic! to register failures, the exit code for httpget was 101 on failures. This could be useful for some things (like being unable to build the async runtime) that represent unrecoverable errors in the setup, but everything else should set the right code.
Luckily, Docker (like most platforms) seems to see a non-zero status code inherently as a failure, so the tool could be used until a fix was implemented. However, the behavior should not be relied on! It is possible that in the future, Docker could set exit codes that are neither 0 or 1 to mark health status as something else, like “unknown”.
After some more fiddling with pipelines and implementing some better dev processes, httpget v0.1.6 was released with TLS support baked in (with rustls)
use reqwest::Client;
use std::{env, process::ExitCode};
async fn run(endpoint: &str) -> Result<(), reqwest::Error> {
let client = Client::builder().build().unwrap();
client.get(endpoint).send().await.map(|_| ())
}
fn main() -> ExitCode {
let args: Vec<String> = env::args().collect();
if args.len() > 2 {
panic!("Too many arguments!")
}
let endpoint = args.last().unwrap();
let res = tokio::runtime::Builder::new_current_thread()
.enable_time()
.enable_io()
.build()
.expect("Could not build the runtime")
.block_on(run(endpoint));
if res.is_ok() {
ExitCode::from(0)
} else {
println!("{}", res.unwrap_err());
ExitCode::from(1)
}
}
#[cfg(test)]
mod tests {
use super::*;
#[tokio::test]
async fn can_reach_google() {
let res = run("http://google.com").await;
assert!(res.is_ok())
}
}
This got a lot closer, but still had some key problems:
- TLS support was now mandatory. My friend didn’t need this, and some of the use cases that I would need something like
httpgetfor also didn’t require TLS, so I wouldn’t want either of us to incur the cost of additional unused dependencies - Since it now supported TLS, the binary was even larger:
4.07mb, or roughly the size of the service container we wanted to use.
For me, this meant that I should go back to the drawing board.
Reassessing Dependencies
A fundamental limit to the binary size came from the dependencies I was using. No matter what I did, I could only use reqwest if I also used tokio. This was far too excessive for my needs!
After a bit more searching, I finally managed to find a package that aligned with my goals: minreq. Although it looks a LOT less used than reqwest - 122 stars, used by 585 projects, about 290k downloads at time of writing compared to 7.1k stars, used by 142k projects, about 48M downloads - it still does what I need it to do. In this case, I considered the benefits of using the most popular package to not outweigh the drawbacks of its bulk: the usecase does not support anything more than a bare-minimum library.
I re-wrote the application to use the new client library instead, which supported minimal dependencies and no async. This means I can now forego having to bundle an async runtime, and making the final tool incredibly minimal.
use std::{env, process::ExitCode};
#[inline]
fn run(endpoint: &str) -> Result<minreq::Response, minreq::Error> {
minreq::get(endpoint).send()
}
fn main() -> ExitCode {
let args: Vec<String> = env::args().collect();
if args.len() > 2 {
panic!("Too many arguments!")
}
let endpoint = args.last().unwrap();
let res = run(endpoint);
if res.is_err() {
println!("{}", res.unwrap_err());
return ExitCode::from(1);
}
let code = res.unwrap().status_code;
if code > 299 {
println!("Received status code {}", code);
return ExitCode::from(1);
}
ExitCode::from(0)
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn can_reach_google() {
let res = run("http://google.com");
assert!(res.is_ok())
}
#[test]
fn cant_reach_nonsense() {
let res = run("http://asdqeqweqweqweqwe.local/qweqweqweqwewqe");
assert!(res.is_err())
}
}
Lastly, I needed to resolve the TLS bundling problem. For that, I ended up learning that you can use features in your own crate to enable features in a dependent crate from reading the Cargo Book section on features. Finally, I updated the pipelines to produce multiple binaries so that users could opt-in to TLS support, or use the regular binary for most condensed but http-only. With that, I released httpget v0.1.7.
Final Review
Let’s look over the requirements list and see where we left off one more time:
| P0 (main priorities) | P1 (key, but less important) | P2 (nice-to-haves) |
|---|---|---|
| HTTP GET requests | 610 kb binary | Automatic Github publishing |
| On success, 0 exit code | Minimal library, fast language | Opt-in TLS support (1.62 mb binary, rustls) |
| On failure, 1 exit code | Easy CLI-ish | Smaller than wget |
| Statically linked |
With this latest version of httpget, the overall binary size is laughably small, making it a reasonably negligible footprint on even the incredibly small service image we were working from. It required only 8 dependencies total to compile with no TLS support, and 25 to include rustls TLS.
From the final binary, my friend was able to mount it to his container as a volume in Docker Compose, and then add a healthcheck as he originally intended. This meant he could still leverage the upstream image publishing, but also monitor container health.
As a last note on binary size, 610kb is very compact. For comparison, a blank “Hello, World!” application compiled with the same target and stripped in the same way is around 400kb. It would be incredibly difficult to get any smaller than that binary size without trying to move to using #[no_std].
What Did I Learn?
As part of this work, I think the most critical (technical) knowledge gain was in how to more effectively use Cargo features. My P2-2 requirement for TLS to be optional could not have been enabled in any other way (that I know of) and it was originally frustrating to work with.
I also learned quite a bit about properly gathering requirements, and double checking with the “client” (i.e. my friend). If I hadn’t been a bit more obsessive over the image size, I probably might not have noticed that I had a P0 that was incorrectly formed.
It was also interesting to see how different targets worked to produce different binary sizes, and what dependencies I could use (or alternatively, that I couldn’t) with my P0 requirement of static linking. For example, I tried to use OpenSSL as the TLS provider at first, but couldn’t figure out a way to get it to link properly, so I gave up in the end and called it a “later problem”.
Finally, I learned more about how binaries get linked, and what that means. To benchmark the existing web clients, I had to figure out how to find the libraries they were linked against so I could get the library sizes, which was new information.
Future Work / Opportunities for Improvement
- Enabling additional features for different TLS providers (i.e. OpenSSL)
- Additional documentation of the package itself
- Allowing
httpgetto receive a sequence of URLs, and querying each one, returning 0 if all of the requests succeed and 1 otherwise. This could be useful if the health of a service cannot be determined from a single route - Using features and conditional compilation to let users choose the HTTP client at compile-time. This could allow someone a little more hesitant to use a less-popular library to still opt for using
reqwestif they want to.